
In your data source, you might have organized your data in several schemas. After adding a new data source in Data Virtuality, you might wonder why not all of your tables are shown.
By default, Data Virtuality will import only a predefined schema. This is set to the most common default schema name of data source (e.g. public for PostgreSQL).
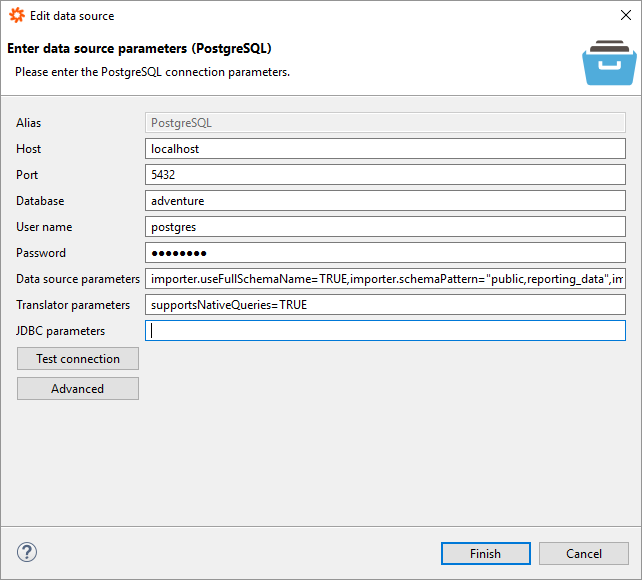
In order to connect to your custom schema, adjust the parameter importer.schemaPattern to either one or a list of multiple schemas, as indicated in the screenshot above.
When specifying multiple schemas, there is the risk of name clashes, when there are two tables named identically in two or more schemas. For having unique table names in Data Virtuality, the parameter importer.useFullSchemaName should always be set to TRUE when dealing with at least two schemas. This will prefix the table names with the schema name in order to have unique fully qualified table names.
Comments
0 comments
Please sign in to leave a comment.